5 Years Later: OpenAJAX Who?
Five years ago the OpenAjax Alliance was founded with the intention of providing interoperability between what was quickly becoming a morass of AJAX-based libraries and APIs. Where is it today, and why has it failed to achieve more prominence? I stumbled recently over a nearly five year old article I wrote in 2006 for Network Computing on the OpenAjax initiative. Remember, AJAX and Web 2.0 were just coming of age then, and mentions of Web 2.0 or AJAX were much like that of “cloud” today. You couldn’t turn around without hearing someone promoting their solution by associating with Web 2.0 or AJAX. After reading the opening paragraph I remembered clearly writing the article and being skeptical, even then, of what impact such an alliance would have on the industry. Being a developer by trade I’m well aware of how impactful “standards” and “specifications” really are in the real world, but the problem – interoperability across a growing field of JavaScript libraries – seemed at the time real and imminent, so there was a need for someone to address it before it completely got out of hand. With the OpenAjax Alliance comes the possibility for a unified language, as well as a set of APIs, on which developers could easily implement dynamic Web applications. A unified toolkit would offer consistency in a market that has myriad Ajax-based technologies in play, providing the enterprise with a broader pool of developers able to offer long term support for applications and a stable base on which to build applications. As is the case with many fledgling technologies, one toolkit will become the standard—whether through a standards body or by de facto adoption—and Dojo is one of the favored entrants in the race to become that standard. -- AJAX-based Dojo Toolkit , Network Computing, Oct 2006 The goal was simple: interoperability. The way in which the alliance went about achieving that goal, however, may have something to do with its lackluster performance lo these past five years and its descent into obscurity. 5 YEAR ACCOMPLISHMENTS of the OPENAJAX ALLIANCE The OpenAjax Alliance members have not been idle. They have published several very complete and well-defined specifications including one “industry standard”: OpenAjax Metadata. OpenAjax Hub The OpenAjax Hub is a set of standard JavaScript functionality defined by the OpenAjax Alliance that addresses key interoperability and security issues that arise when multiple Ajax libraries and/or components are used within the same web page. (OpenAjax Hub 2.0 Specification) OpenAjax Metadata OpenAjax Metadata represents a set of industry-standard metadata defined by the OpenAjax Alliance that enhances interoperability across Ajax toolkits and Ajax products (OpenAjax Metadata 1.0 Specification) OpenAjax Metadata defines Ajax industry standards for an XML format that describes the JavaScript APIs and widgets found within Ajax toolkits. (OpenAjax Alliance Recent News) It is interesting to see the calling out of XML as the format of choice on the OpenAjax Metadata (OAM) specification given the recent rise to ascendancy of JSON as the preferred format for developers for APIs. Granted, when the alliance was formed XML was all the rage and it was believed it would be the dominant format for quite some time given the popularity of similar technological models such as SOA, but still – the reliance on XML while the plurality of developers race to JSON may provide some insight on why OpenAjax has received very little notice since its inception. Ignoring the XML factor (which undoubtedly is a fairly impactful one) there is still the matter of how the alliance chose to address run-time interoperability with OpenAjax Hub (OAH) – a hub. A publish-subscribe hub, to be more precise, in which OAH mediates for various toolkits on the same page. Don summed it up nicely during a discussion on the topic: it’s page-level integration. This is a very different approach to the problem than it first appeared the alliance would take. The article on the alliance and its intended purpose five years ago clearly indicate where I thought this was going – and where it should go: an industry standard model and/or set of APIs to which other toolkit developers would design and write such that the interface (the method calls) would be unified across all toolkits while the implementation would remain whatever the toolkit designers desired. I was clearly under the influence of SOA and its decouple everything premise. Come to think of it, I still am, because interoperability assumes such a model – always has, likely always will. Even in the network, at the IP layer, we have standardized interfaces with vendor implementation being decoupled and completely different at the code base. An Ethernet header is always in a specified format, and it is that standardized interface that makes the Net go over, under, around and through the various routers and switches and components that make up the Internets with alacrity. Routing problems today are caused by human error in configuration or failure – never incompatibility in form or function. Neither specification has really taken that direction. OAM – as previously noted – standardizes on XML and is primarily used to describe APIs and components - it isn’t an API or model itself. The Alliance wiki describes the specification: “The primary target consumers of OpenAjax Metadata 1.0 are software products, particularly Web page developer tools targeting Ajax developers.” Very few software products have implemented support for OAM. IBM, a key player in the Alliance, leverages the OpenAjax Hub for secure mashup development and also implements OAM in several of its products, including Rational Application Developer (RAD) and IBM Mashup Center. Eclipse also includes support for OAM, as does Adobe Dreamweaver CS4. The IDE working group has developed an open source set of tools based on OAM, but what appears to be missing is adoption of OAM by producers of favored toolkits such as jQuery, Prototype and MooTools. Doing so would certainly make development of AJAX-based applications within development environments much simpler and more consistent, but it does not appear to gaining widespread support or mindshare despite IBM’s efforts. The focus of the OpenAjax interoperability efforts appears to be on a hub / integration method of interoperability, one that is certainly not in line with reality. While certainly developers may at times combine JavaScript libraries to build the rich, interactive interfaces demanded by consumers of a Web 2.0 application, this is the exception and not the rule and the pub/sub basis of OpenAjax which implements a secondary event-driven framework seems overkill. Conflicts between libraries, performance issues with load-times dragged down by the inclusion of multiple files and simplicity tend to drive developers to a single library when possible (which is most of the time). It appears, simply, that the OpenAJAX Alliance – driven perhaps by active members for whom solutions providing integration and hub-based interoperability is typical (IBM, BEA (now Oracle), Microsoft and other enterprise heavyweights – has chosen a target in another field; one on which developers today are just not playing. It appears OpenAjax tried to bring an enterprise application integration (EAI) solution to a problem that didn’t – and likely won’t ever – exist. So it’s no surprise to discover that references to and activity from OpenAjax are nearly zero since 2009. Given the statistics showing the rise of JQuery – both as a percentage of site usage and developer usage – to the top of the JavaScript library heap, it appears that at least the prediction that “one toolkit will become the standard—whether through a standards body or by de facto adoption” was accurate. Of course, since that’s always the way it works in technology, it was kind of a sure bet, wasn’t it? WHY INFRASTRUCTURE SERVICE PROVIDERS and VENDORS CARE ABOUT DEVELOPER STANDARDS You might notice in the list of members of the OpenAJAX alliance several infrastructure vendors. Folks who produce application delivery controllers, switches and routers and security-focused solutions. This is not uncommon nor should it seem odd to the casual observer. All data flows, ultimately, through the network and thus, every component that might need to act in some way upon that data needs to be aware of and knowledgeable regarding the methods used by developers to perform such data exchanges. In the age of hyper-scalability and über security, it behooves infrastructure vendors – and increasingly cloud computing providers that offer infrastructure services – to be very aware of the methods and toolkits being used by developers to build applications. Applying security policies to JSON-encoded data, for example, requires very different techniques and skills than would be the case for XML-formatted data. AJAX-based applications, a.k.a. Web 2.0, requires different scalability patterns to achieve maximum performance and utilization of resources than is the case for traditional form-based, HTML applications. The type of content as well as the usage patterns for applications can dramatically impact the application delivery policies necessary to achieve operational and business objectives for that application. As developers standardize through selection and implementation of toolkits, vendors and providers can then begin to focus solutions specifically for those choices. Templates and policies geared toward optimizing and accelerating JQuery, for example, is possible and probable. Being able to provide pre-developed and tested security profiles specifically for JQuery, for example, reduces the time to deploy such applications in a production environment by eliminating the test and tweak cycle that occurs when applications are tossed over the wall to operations by developers. For example, the jQuery.ajax() documentation states: By default, Ajax requests are sent using the GET HTTP method. If the POST method is required, the method can be specified by setting a value for the type option. This option affects how the contents of the data option are sent to the server. POST data will always be transmitted to the server using UTF-8 charset, per the W3C XMLHTTPRequest standard. The data option can contain either a query string of the form key1=value1&key2=value2 , or a map of the form {key1: 'value1', key2: 'value2'} . If the latter form is used, the data is converted into a query string using jQuery.param() before it is sent. This processing can be circumvented by setting processData to false . The processing might be undesirable if you wish to send an XML object to the server; in this case, change the contentType option from application/x-www-form-urlencoded to a more appropriate MIME type. Web application firewalls that may be configured to detect exploitation of such data – attempts at SQL injection, for example – must be able to parse this data in order to make a determination regarding the legitimacy of the input. Similarly, application delivery controllers and load balancing services configured to perform application layer switching based on data values or submission URI will also need to be able to parse and act upon that data. That requires an understanding of how jQuery formats its data and what to expect, such that it can be parsed, interpreted and processed. By understanding jQuery – and other developer toolkits and standards used to exchange data – infrastructure service providers and vendors can more readily provide security and delivery policies tailored to those formats natively, which greatly reduces the impact of intermediate processing on performance while ensuring the secure, healthy delivery of applications. API Jabberwocky: You Say Tomay-to and I Say Potah-to OpenAjax Metadata 1.0 and the Adobe Dreamweaver Widget Browser OpenAjax Alliance AJAX-based Dojo Toolkit The Stealthy Ascendancy of JSON JSON Continues its Winning Streak Over XML JSON versus XML: Your Choice Matters More Than You Think I am in your HTTP headers, attacking your application The Web 2.0 API: From collaborating to compromised IT as a Service: A Stateless Infrastructure Architecture Model JSON Activity Streams and the Other Consumerization of IT351Views0likes0CommentsProgrammability in the Network: Canary Deployments
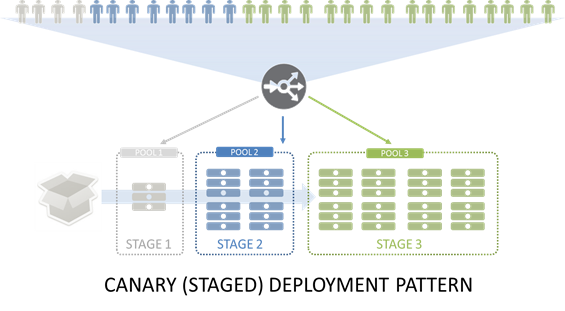
#devops The canary deployment pattern is another means of enabling continuous delivery. Deployment patterns (or as I like to call them of late, devops patterns) are good examples of how devops can put into place systems and tools that enable continuous delivery to be, well, continuous. The goal of these patterns is, for the most part, to make sure operations can smoothly move features, functions, releases or applications into production. We've previously looked at the Blue Green deployment pattern and today we're going to look at a variation: Canary deployments. Canary deployments are applicable when you're running a cluster of servers. In other words, you've got lots and lots of (probably active right now while you're considering pushing that next release) users. What you don't want is to do the traditional "we're sorry, we're down for maintenance, here's a picture of a funny squirrel to amuse you while you wait" maintenance page. You want to be able to roll out the new release without disruption. Yeah, that's quite the ask, isn't it? The Canary deployment pattern is an incremental upgrade methodology. First, the build is pushed to a small set of servers to which only a select group of users are directed. If that goes well, the release is pushed to a larger set of servers with a limited set of users. Finally, if that goes well, then the release is pushed out to all servers and all users. If issues occur at any stage, the release is halted - it goes no further. Hence the naming of the pattern - after the miner's canary, used because "its demise provided a warning of dangerous levels of toxic gases". The trick to implementing this pattern is two fold: first, being able to group the servers used in each step into discrete pools and second, the ability to direct specific sets of users to the appropriate pools. Both capabilities requires the ability to execute some logic to perform user-based load balancing. Nolio, in its first Devops Best Practices video, implements Canary deployments by manipulating the pools of servers at the load balancing tier, removing them to upgrade and then reinserting them for testing before moving onto the next phase. If your load balancing solution is programmable, there's no need to actually remove them as you can simply insert logic to remove them from being selected until they've been upgraded. You can also then insert the logic to determine which users are directed to which pool of servers. If the load balancing platform is really programmable, you can even extend that to determination to querying a database to determine user inclusion in certain groups, such as those you might use to perform AB testing. Such logic might base the decision on IP address (not the best option but an option) or later, when you're actually rolling out to a percentage of users you can write logic that randomly selects users based on location or their user name - like sharding, only in reverse - or pretty much anything you can think of. You can even split that further if you're rolling out an update to an API that's used by both mobile and traditional clients, to catch both or neither or specific types in an orderly fashion so you can test methodically - because you want to test methodically when you're using live users as test subjects. The beauty of this pattern is that allows continuous delivery. Users are never disrupted (if you do it right) and the upgrade occurs in a safely staged, incremental fashion. That enables you to back out quickly if necessary, because you do have a back button plan, right? Right?807Views1like1Comment
iControl REST 101: Modifying Objects
So far in this series we’ve shown you how to connect to iControl REST via cURL, how to list objects on the device (which is probably the most used command for most APIs, including ours), and how to add objects. So you’re currently able to get a system up and running and configure new services on your BIG-IP. What if, however, you want to modify things that are already running? For that, you need a modify command. Enter PUT. Remember that in REST based architectures the API is able to determine what type of action you’re performing, and thereby the arguments and structure it should expect to parse coming in, based on the type of HTTP(S) transaction. For us a GET is a list, a POST is an add, and to modify things, you use PUT. This allows the system to understand that you’re going to reference an object that already exists, and modify some of the contents. It is important that the API back end can tell the difference. If you just tried to do another POST with only the arguments you wanted to change, it would fail because you wouldn’t meet the minimum requirements. Without a PUT, you’d have to do a list on the object, save all the configuration options already on the system for that object, modify just the one you wanted to change in your memory structure, delete the object on the system, and then POST all of that data, including the one or two modified fields, back to the device. That’s way too much work. Instead, let’s just learn how to modify, shall we? Fortunately it’s simple. All you need to do is format your cURL request with a PUT and the data you want to modify, and you’re all set. First let’s list the object we want to modify, so you can see what it looks like as it sits on the box currently. For that we go back to our list command: curl -sk -u admin:admin https://dev.rest.box/mgmt/tm/net/self/cw_test2 | jq . So that’s what the object looks like Now what if we want to simply make that existing self IP address available for more than one port? We can use the “allowService” flag to do this. By setting it to “all” we’ll allow that IP to answer on any port, rather than just a specific one, thereby opening up our config a bit. So we have the object we want to modify as well as the attribute we want to modify for that object. All we need now is to send the command to do the work. Fortunately this is pretty easy, as I mentioned before. You use the same cURL structure as always with the –sk and user:pass supplied. This will look nearly identical to the add command with the changes being that we use the “PUT” method instead of “POST” and we only supply the one item we’re modifying about the object. It looks like this: curl -sk -u admin:admin https://dev.rest.box/mgmt/tm/net/self/cw_test2 -H "Content-Type: application/json" -X PUT -d "{\"allowService\":\"all\"}" | jq . Notice that I’m still piping the output to jq here. This is because the response from the API when running most commands such as POST and PUT is actually quite useful. Here’s what I get when I run the above command: As you can see this returns the entire, new output of the object, including the piece that got modified. In this case it’s the sixth line of output, including the brace lines. What used to be the line defining the vlan is now "allowService": "all", just like we wanted. So there you have it, modifying objects on the BIG-IP remotely doesn’t get much easier than that. Armed with this knowledge on top of what we’ve covered in previous installments you’ll be able to tackle 90% of the challenges you might encounter. For our next and penultimate edition of this series we’ll cover the delete command, which should round out the methods you’ll need for the general application of the new iControl REST API.882Views1like8CommentsDNS Profile Benefits in iRules
I released an article a while back on the DNS services architecture now built in to BIG-IP, as well as a solution article that showed some fancy DNS tricks utilizing the architecture to black hole malicious DNS requests. What might be lost in those articles is the difference maker the dns profile makes in using iRules to return DNS responses. I was working on a little project earlier this week and the VM I am hosting requires a single DNS response to a single question. The problem is that I don't have the particular fqdn defined in an external or internal name server. Adding the fqdn to either is problematic: Adding the FQDN to the external name server would require adding an internal view to bind, which adds risk and complexity. Adding the FQDN to the internal name server would require adding external zones to my internal server, which adds unnecessary complexity. So as I wasn't going down either of those roads...I had to find an alternate solution. Thankfully, I have BIG-IP VE at my disposal, and therefore, iRules. The DNS profile exposes in iRules the DNS:: namespace, and with it, native decodes for all the fields in requests/responses. The iRule, with the DNS namespace, is trivial: when DNS_REQUEST { if { [IP::addr [IP::remote_addr] equals 192.168.1.0/24] && ([DNS::question name] equals "www.mytest.com") } { DNS::answer insert "[DNS::question name]. 111 [DNS::question class] [DNS::question type] 192.168.1.200" DNS::return } else ( discard } } However, after trying to save the iRule, I realized I'm not licensed for dns services on my BIG-IP VE, so that path wouldn't work. So I took a packet capture of some local dns traffic on my desktop and started mapping the fields and preparing to settle in for some serious binary scan/format work, but then remembered there were already some iRules out in the codeshare that I though might get me started. Natty76's Fast DNS 2 seemed to fit the bill. So with just a little customization, I was up and running with no issues. But notice the amount of work required (both by author and by system resources) to make this happen when compared with the above iRule. when RULE_INIT priority 1 { # Domain Name = www mytest com set static::domain "www.mytest.com" # IP address in answer section (type A) set static::answer_string "192.168.1.200" } when RULE_INIT { # Header generation (in hexadecimal) # qr(1) opcode(0000) AA(1) TC(0) RD(1) RA(1) Z(000) RCODE(0000) set static::header "8580" # 1 question, X answer, 0 NS, 0 Addition set static::answer_record [format %04x [llength $static::answer_string]] set static::header "${static::header}0001${static::answer_record}00000000" # generate domain binary string set static::domainhex "" foreach static::d [split $static::domain "."] { set static::l [string length $static::d] scan $static::l %d static::h append static::domainhex [format %02x $static::h] foreach static::n [split $static::d ""] { scan $static::n %c static::h append static::domainhex [format %02x $static::h] } } set static::domainbin [binary format H* $static::domainhex] append static::domainhex 00 set static::answerhead $static::domainhex # Type = A set static::answerhead "${static::answerhead}0001" # Class = IN set static::answerhead "${static::answerhead}0001" # TTL = 1 day set static::answerhead "${static::answerhead}00015180" # Data length = 4 set static::answerhead "${static::answerhead}0004" set static::answer "" foreach static::a $static::answer_string { scan $static::a "%d.%d.%d.%d" a b c d append static::answer "${static::answerhead}[format %02x%02x%02x%02x $a $b $c $d]" } } when CLIENT_DATA { if { [IP::addr [IP::client_addr] equals 192.168.1.0/22] } { binary scan [UDP::payload] H4@12A*@12H* id dname question set dname [string tolower [getfield $dname \x00 1 ] ] switch -glob $dname \ $static::domainbin { #log local0. "match" set hex ${id}${static::header}${question}${static::answer} set payload [binary format H* $hex ] # to drop only a packet and keep UDP connection, use UDP::drop drop UDP::respond $payload } \ default { #log local0. "does not match" } } else { discard } } No native decode means you have to do all the decoding work of the protocol yourself. I don't get to share "from the trenches" as much as I used to, but this was too good a demonstration to pass up.390Views0likes3Comments20 Lines or Less #1
Yesterday I got an idea for what I think will be a cool new series that I wanted to bring to the community via my blog. I call it "20 lines or less". My thought is to pose a simple question: "What can you do via an iRule in 20 lines or less?". Each week I'll find some cool examples of iRules doing fun things in less than 21 lines of code, not counting white spaces or comments, round them up, and post them here. Not only will this give the community lots of cool examples of what iRules can do with relative ease, but I'm hoping it will continue to show just how flexible and light-weight this technology is - not to mention just plain cool. I invite you to follow along, learn what you can and please, if you have suggestions, contributions, or feedback of any kind, don't hesitate to comment, email, IM, whatever. You know how to get a hold of me...please do. ;) I'd love to have a member contributed version of this once a month or quarter or ... whatever if you guys start feeding me your cool, short iRules. Ok, so without further adieu, here we go. The inaugural edition of 20 Lines or Less. For this first edition I wanted to highlight some of the things that have already been contributed by the awesome community here at DevCentral. So I pulled up the Code Share and started reading. I was quite happy to see that I couldn't even get halfway through the list of awesome iRule contributions before I found 5 entries that were neat, and under 20 lines (These are actually almost all under 10 lines of code - wow!) Kudos to the contributors. I'll grab another bunch next week to keep highlighting what we've got already! Cipher Strength Pool Selection Ever want to check the type of encryption your users are using before allowing them into your most secure content? Here's your solution. when HTTP_REQUEST { log local0. "[IP::remote_addr]: SSL cipher strength is [SSL::cipher bits]" if { [SSL::cipher bits] < 128 }{ pool weak_encryption_pool } else { pool strong_encryption_pool } } Clone Pool Based On URI Need to clone some of your traffic to a second pool, based on the incoming URI? Here you go... when HTTP_REQUEST { if { [HTTP::uri] starts_with "/clone_me" } { pool real_pool clone pool clone_pool } else { pool real_pool } } Cache No POST Have you been looking for a way to avoid sending those POST responses to your RAMCache module? You're welcome. when HTTP_REQUEST { if { [HTTP::method] equals "POST" } { CACHE::disable } else { CACHE::enable } } Access Control Based on IP Here's a great example of blocking unwelcome IP addresses from accessing your network and only allowing those Client-IPs that you have deemed trusted. when CLIENT_ACCEPTED { if { [matchclass [IP::client_addr] equals $::trustedAddresses] }{ #Uncomment the line below to turn on logging. #log local0. "Valid client IP: [IP::client_addr] - forwarding traffic" forward } else { #Uncomment the line below to turn on logging. #log local0. "Invalid client IP: [IP::client_addr] - discarding" discard } } Content Type Tracking If you're looking to keep track of the different types of content you're serving, this iRule can help in a big way. # First, create statistics profile named "ContentType" with following entries: # HTML # Images # Scripts # Documents # Stylesheets # Other # Now associate this Statistics Profile to the virtual server. Then apply the following iRule. # To view the results, go to Statistics -> Profiles - Statistics when HTTP_RESPONSE { switch -glob [HTTP::header "Content-type"] { image/* { STATS::incr "ContentType" "Images" } text/html { STATS::incr "ContentType" "HTML" } text/css { STATS::incr "ContentType" "Stylesheets" } *javascript { STATS::incr "ContentType" "Scripts" } text/vbscript { STATS::incr "ContentType" "Scripts" } application/pdf { STATS::incr "ContentType" "Documents" } application/msword { STATS::incr "ContentType" "Documents" } application/*powerpoint { STATS::incr "ContentType" "Documents" } application/*excel { STATS::incr "ContentType" "Documents" } default { STATS::incr "ContentType" "Other" } } } There you have it, the first edition of "20 Lines or Less"! I hope you enjoyed it...I sure did. If you've got feedback or examples to be featured in future editions, let me know. #Colin4.5KViews1like1CommentIntroducing a RESTful interface for iControl
iControl isn’t just SOAP anymore… No, iControl isn’t getting lazy. While taking it easy is an important part of life, I’m talking about the other kind of REST. REST, or “REpresentational State Transfer” for you technically inclined, is a style of architectural principals with which you can design web services that focus on a system’s resources. It also defines how resource states are addressed and transferred over the network. REST is really a “style” of getting and setting resources and doesn’t define the underlying communications. Most implementations out there make use of HTTP and JSON as a content format, which is what we’ve chosen to do as well. There are plenty of articles on the web that compare and contrast SOAP and REST, so I won’t get into those here. I’m also not going to go really deep into the principals of REST as you can find dozens of those easily with a web search. In this article, I’ll discuss how we’ve chosen to implement our REST interface for iControl and give you some examples on how to use it. Oh, and don’t get any ideas that our SOAP based interface is going anywhere. We are creating our REST interfaces as an alternate method for performing automation and monitoring. We don’t currently have plans on ceasing development on our SOAP interface. iControl-REST The REST interface for iControl was introduced in BIG-IP version 11.4. For this release, we are considering the feature as “Early Access”. Call it beta or whatever you want. But what that really means is that it will change in our next release. We are using this release for feedback from the users out there to find out what works and what doesn’t. Several key features are not implemented yet (for example versioning) which we have targeted for an upcoming product release when we finalize the implementation. Ok, with that said, now we can get into the details. iControl-REST, like it’s SOAP counterpart, is implemented on HTTPS and uses the same authentication and authorization roles for user access. We support the following HTTP commands: GET - for retrieving (ie. Querying the status of a Pool) POST - for creating (ie. Creating a Pool Member) PUT - for updating (ie. Changing the load balancing method on a Pool) DELETE - for deleting (ie. Deleting a Virtual Server) And, the format of the requests and responses is JSON. Starting the iControl REST Service (icrd) Run the “modify sys service icrd” TMSH command to add and start the iControl REST service. Notice the nice “EA” warning. root@(BIG-IP1)(…)(tmos) # modify sys service ircd add WARNING: This early-access feature comes with minimal documentation and testing. Version control is not implemented; therefore any scripts that you write using this API version may not work with subsequent releases. root@(BIG-IP1)(…)(tmos) # Once the service is running, you can use the “show sys service”, “stop sys service” and “start sys service” TMSH commands to monitor and control the status of the iControl REST service. Writing Your First Script Since iControl-REST is just using HTTPS, you can use any scripting technology you heart desires. For this article, we’ll use the command line tool cURL. It’s cross platform, so you should be able to wrap a bash script for Unix, Mac, etc or PowerShell for Windows around it very easily. Use the “-u” parameter to pass in the user credentials, the “-X” parameter to specify the HTTP method, and the uri for the resource you wish to access. curl -k -u user:pass -X http-method uri The URI format is as follows Module URI https://management-ip/mgmt/tm/module This access all of the sub-modules and/or components under the given module (ltm, gtm, etc). Sub-module URI https://management-ip/mgmt/tm/module/sub-module This access all of the sub-modules and/or components under the given sub-module. Component URI https://management-ip/mgmt/tm/module[/sub-module]/component This accesses the details about the given component. The tmsh Traffic Management Shell Reference documents the hierarchy of modules and components, and identifies the details of each component. Example This curl command will query all of the information about the ltm module. $ curl -k -u user:pass -H “Content-Type: application/json” -X GET https://bigip_ip/mgmt/tm/ltm { "currentItemCount": 22, "items": [ { "reference": { "link": "https://bigip_ip/mgmt/tm/ltm/auth" } }, { "reference": { "link": "https://bigip_ip/mgmt/tm/ltm/data-group" } }, { "reference": { "link": "https://bigip_ip/mgmt/tm/ltm/dns" } } ... ], "kind": "tm:ltm:ltmstate", "pageIndex": 1, "partition": "/Common/", "selfLink": "https://bigip-ip/mgmt/tm/ltm", "startIndex": 1, "totalItems": 22, "totalPages": 1 } User Guide For this release, we have provided a User Guide to assist in getting started with using the new REST interface. It can be downloaded from this link: iControlRest-UserGuide.pdf. We would love to hear your feedback on using iControl-REST. Any and all comments and questions should be posted to the iControl group. -Joe2.6KViews0likes10CommentsNewton's First Law of Devops
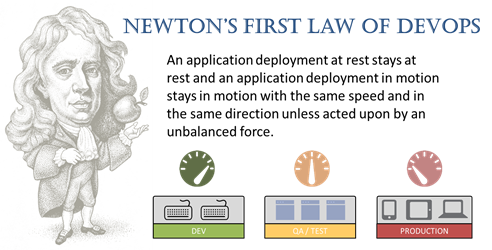
#devops Deployment patterns enabling continuous delivery help align operations with development - and keep user frustration to a minimum One of the most difficult transitions for operations to make is the need to support releases more frequently. While most organizations will never match the velocity of a Facebook or Netflix, there is still a desire to eliminate the "reduced speed zone" most applications run into when trying to move into production. The reason for the reduced speed zone is the potential for downtime, not only for the application (version) being released but for other applications and services dependent on the same infrastructure. Misconfiguration is, after all, the leading cause of downtime in data centers across the globe. Thus, operations has good reason to be wary. And yet reducing the speed at which an application actually moves into production is exactly the opposite direction application development - and the business - want to go. They want to go faster, to be more agile, to release incrementally. Because application development rules today follow Newton's First Law of Motion: an object at rest stays at rest and an object in motion stays in motion with the same speed and in the same direction unless acted upon by an unbalanced force. Operations does not want to be that unbalanced force that stops the object. That's why we're seeing more "deployment patterns" or "devops patterns". That's why we're seeing an increasing need for programmability in the data path, i.e. in the network. Today, the complexity of infrastructure in production environments - the network, the application infrastructure, the point solutions, the services - impedes continuous deployment efforts by failing to meet devops need to not just automate, but implement the patterns and emerging architectures that keep deployments moving in the same direction and with the same speed as they are released by developers. These patterns depend on agility that is achieved primarily through programmability. Whether it's to implement blue-green deployments, a/b testing, versioning patterns or canary deployments - devops is in need of a devops platform, if you will, that will provide the programmability necessary to implement the deployment patterns that enable continuous delivery. A platform that eliminates the unbalanced force that has traditionally slowed down the release cycle, frustrating users and the business alike. That platform needs to be fast, flexible, and programmable. It needs to be able to bridge the gap between traditional and modern infrastructure. It needs to be API-enabled and yet easy to manage. More than anything else, that platform needs to exist.409Views0likes2CommentsBIG-IP LTM VE: Transfer your iRules in style with the iRule Editor
The new LTM VE has opened up the possibilities for writing, testing and deploying iRules in a big way. It’s easier than ever to get a test environment set up in which you can break things develop to your heart’s content. This is fantastic news for us iRulers that want to be doing the newest, coolest stuff without having to worry about breaking a production system. That’s all well and good, but what the heck do you do to get all of your current stuff onto your test system? There are several options, ranging from copy and paste (shudder) to actual config copies and the like, which all work fine. Assuming all you’re looking for though is to transfer over your iRules, like me, the easiest way I’ve found is to use the iRule editor’s export and import features. It makes it literally a few clicks and super easy to get back up and running in the new environment. First, log into your existing LTM system with your iRule editor (you are using the editor, right? Of course you are…just making sure). You’ll see a screen something like this (right) with a list of a bagillionty iRules on the left and their cool, color coded awesomeness on the right. You can go through and select iRules and start moving them manually, but there’s really no need. All you need to do is go up to the File –> Archive –> Export option and let it do its magic. All it’s doing is saving text files to your local system to archive off all of your iRuley goodness. Once that’s done, you can then spin up your new LTM VE and get logged in via the iRule editor over there. Connect via the iRule editor, and go to File –> Archive –> Import, shown below. Once you choose the import option you’ll start seeing your iRules popping up in the left-hand column, just like you’re used to. This will take a minute depending on how many iRules you have archived (okay, so I may have more than a few iRules in my collection…) but it’s generally pretty snappy. One important thing to note at his point, however, is that all of your iRules are bolded with an asterisk next to them. This means they are not saved in their current state on the LTM. If you exit at this point, you’ll still be iRuleless, and no one wants that. Luckily Joe thought of that when building the iRule editor, so all you need to do is select File –> Save All, and you’ll be most of the way home. I say most of the way because there will undoubtedly be some errors that you’ll need to clean up. These will be config based errors, like pools that used to exist on your old system and don’t now, etc. You can either go create the pools in the config or comment out those lines. I tend to try and keep my iRules as config agnostic as possible while testing things, so there aren’t a ton of these but some of them always crop up. The editor makes these easy to spot and fix though. The name of the iRule that’s having a problem will stay bolded and any errors in that particular code will be called out (assuming you have that feature turned on) so you can pretty quickly spot them and fix them. This entire process took me about 15 minutes, including cleaning up the code in certain iRules to at least save properly on the new system, and I have a bunch of iRules, so that’s a pretty generous estimate. It really is quick, easy and painless to get your code onto an LTM VE and get hacking coding. An added side benefit, but a cool one, is that you now have your iRules backed up locally. Not only does this mean you’re double plus sure that they won’t be lost, but it means the next time you want to deploy them somewhere, all you have to do is import from the editor. So if you haven’t yet, go download your BIG-IP LTM VE and get started. I can’t recommend it enough. Also make sure to check out some of the really handy DC content that shows you how to tweak it for more interfaces or Joe’s supremely helpful guide on how to use a single VM to run an entire client/LTM/server setup. Wicked cool stuff. Happy iRuling. #Colin1.3KViews0likes1CommentHosting Sorry, Error, or Maintenance Pages on BIG-IP LTM with iRules
Note Whereas you can still customize your BIG-IP with perl-scripts and sorry pages in this way, F5 has made this far easier with iFiles, introduced in 11.1. This tech tip on iFiles should be the recommended path for sorry pages going forward. I’ve posted on this before (Host that Sorry Page on your BIG-IP!) but it’s been a while and there have been a few updates. Besides, narrowing the application to only sorry pages is a bit myopic—I’m sure my BIG-IP is offended that I treated it so callously. Anyway, I got an inquiry a week or so ago about the images in tables not being picked up by the script. The images in the table were referenced as such: #<table background="genericofflinebackground.gif" align="center" width="1024" height="768" > I reached out to the author, Kirk Bauer, and he gave me some pointers as where to look. There’s a function in the perl script that parses the html to look for items of interest: sub start { my ($self, $tag, $attr, $attrseq, $origtext) = @_; # print out original text if ($tag eq 'img') { if ($attr->{'src'}) { $attr->{'src'} = &handle_object($tag, 'src', $attr->{'src'}); } } Modifying the if ($tag..) conditional to match the table wasn’t that hard at all: sub start { my ($self, $tag, $attr, $attrseq, $origtext) = @_; # print out original text if ($tag eq 'img') { if ($attr->{'src'}) { $attr->{'src'} = &handle_object($tag, 'src', $attr->{'src'}); } } if ($tag eq 'table') { if ($attr->{'background'}) { $attr->{'background'} = &handle_object($tag, 'background', $attr->{'background'}); } } That solved problem number one. The second problem with the script was that it wasn’t asking about partition preference, rather it just dumped the iRule and datagroups into the last partition defined in bigip.conf. This was strange, as the code to handle partitions was in place: my @partitions; open (CONF, "/config/bigip.conf") or die "Could not read /config/bigip.conf: $!\n"; while (my $line = <CONF>) { if ($line =~ /^partition (.+) {/) { push @partitions, $1; } } The problem is that the regex is trying to match “partition <my partition> {“ and that is (at least in 10.2.1 HF3) no longer in the bigip.conf file. It has been moved to bigip_sys.conf. Updating the code as shown below solved the issue and now the user is asked for the appropriate partition and the iRule and datagroup gets deployed as expected. my @partitions; open (CONF, "/config/bigip_sys.conf") or die "Could not read /config/bigip_sys.conf: $!\n"; while (my $line = <CONF>) { if ($line =~ /^partition (.+) {/) { push @partitions, $1; } } For the full script, head to the iRules wiki entry LTM Maintenance Page Generator and grab version 2.2. Related Articles Host that Sorry Page on your BIG-IP! about i-rule sorry page configuration - DevCentral - F5 DevCentral ... DevCentral Wiki: Automatic_maintenance_page___ Sorry_page_with_images DevCentral Wiki: Sorry Page I Rule Generator_ Perl DevCentral Wiki: LTM Maintenance Page Generator DevCentral Wiki: CodeShare Sorry Page when Severs are down - DevCentral - F5 DevCentral ... Site Dwon Page form https virtual server - DevCentral - F5 ...816Views0likes3CommentsThe Challenges of SQL Load Balancing
#infosec #iam load balancing databases is fraught with many operational and business challenges. While cloud computing has brought to the forefront of our attention the ability to scale through duplication, i.e. horizontal scaling or “scale out” strategies, this strategy tends to run into challenges the deeper into the application architecture you go. Working well at the web and application tiers, a duplicative strategy tends to fall on its face when applied to the database tier. Concerns over consistency abound, with many simply choosing to throw out the concept of consistency and adopting instead an “eventually consistent” stance in which it is assumed that data in a distributed database system will eventually become consistent and cause minimal disruption to application and business processes. Some argue that eventual consistency is not “good enough” and cite additional concerns with respect to the failure of such strategies to adequately address failures. Thus there are a number of vendors, open source groups, and pundits who spend time attempting to address both components. The result is database load balancing solutions. For the most part such solutions are effective. They leverage master-slave deployments – typically used to address failure and which can automatically replicate data between instances (with varying levels of success when distributed across the Internet) – and attempt to intelligently distribute SQL-bound queries across two or more database systems. The most successful of these architectures is the read-write separation strategy, in which all SQL transactions deemed “read-only” are routed to one database while all “write” focused transactions are distributed to another. Such foundational separation allows for higher-layer architectures to be implemented, such as geographic based read distribution, in which read-only transactions are further distributed by geographically dispersed database instances, all of which act ultimately as “slaves” to the single, master database which processes all write-focused transactions. This results in an eventually consistent architecture, but one which manages to mitigate the disruptive aspects of eventually consistent architectures by ensuring the most important transactions – write operations – are, in fact, consistent. Even so, there are issues, particularly with respect to security. MEDIATION inside the APPLICATION TIERS Generally speaking mediating solutions are a good thing – when they’re external to the application infrastructure itself, i.e. the traditional three tiers of an application. The problem with mediation inside the application tiers, particularly at the data layer, is the same for infrastructure as it is for software solutions: credential management. See, databases maintain their own set of users, roles, and permissions. Even as applications have been able to move toward a more shared set of identity stores, databases have not. This is in part due to the nature of data security and the need for granular permission structures down to the cell, in some cases, and including transactional security that allows some to update, delete, or insert while others may be granted a different subset of permissions. But more difficult to overcome is the tight-coupling of identity to connection for databases. With web protocols like HTTP, identity is carried along at the protocol level. This means it can be transient across connections because it is often stuffed into an HTTP header via a cookie or stored server-side in a session – again, not tied to connection but to identifying information. At the database layer, identity is tightly-coupled to the connection. The connection itself carries along the credentials with which it was opened. This gives rise to problems for mediating solutions. Not just load balancers but software solutions such as ESB (enterprise service bus) and EII (enterprise information integration) styled solutions. Any device or software which attempts to aggregate database access for any purpose eventually runs into the same problem: credential management. This is particularly challenging for load balancing when applied to databases. LOAD BALANCING SQL To understand the challenges with load balancing SQL you need to remember that there are essentially two models of load balancing: transport and application layer. At the transport layer, i.e. TCP, connections are only temporarily managed by the load balancing device. The initial connection is “caught” by the Load balancer and a decision is made based on transport layer variables where it should be directed. Thereafter, for the most part, there is no interaction at the load balancer with the connection, other than to forward it on to the previously selected node. At the application layer the load balancing device terminates the connection and interacts with every exchange. This affords the load balancing device the opportunity to inspect the actual data or application layer protocol metadata in order to determine where the request should be sent. Load balancing SQL at the transport layer is less problematic than at the application layer, yet it is at the application layer that the most value is derived from database load balancing implementations. That’s because it is at the application layer where distribution based on “read” or “write” operations can be made. But to accomplish this requires that the SQL be inline, that is that the SQL being executed is actually included in the code and then executed via a connection to the database. If your application uses stored procedures, then this method will not work for you. It is important to note that many packaged enterprise applications rely upon stored procedures, and are thus not able to leverage load balancing as a scaling option. Depending on your app or how your organization has agreed to protect your data will determine which of these methods are used to access your databases. The use of inline SQL affords the developer greater freedom at the cost of security, increased programming(to prevent the inherent security risks), difficulty in optimizing data and indices to adapt to changes in volume of data, and deployment burdens. However there is lively debate on the values of both access methods and how to overcome the inherent risks. The OWASP group has identified the injection attacks as the easiest exploitation with the most damaging impact. This also requires that the load balancing service parse MySQL or T-SQL (the Microsoft Transact Structured Query Language). Databases, of course, are designed to parse these string-based commands and are optimized to do so. Load balancing services are generally not designed to parse these languages and depending on the implementation of their underlying parsing capabilities, may actually incur significant performance penalties to do so. Regardless of those issues, still there are an increasing number of organizations who view SQL load balancing as a means to achieve a more scalable data tier. Which brings us back to the challenge of managing credentials. MANAGING CREDENTIALS Many solutions attempt to address the issue of credential management by simply duplicating credentials locally; that is, they create a local identity store that can be used to authenticate requests against the database. Ostensibly the credentials match those in the database (or identity store used by the database such as can be configured for MSSQL) and are kept in sync. This obviously poses an operational challenge similar to that of any distributed system: synchronization and replication. Such processes are not easily (if at all) automated, and rarely is the same level of security and permissions available on the local identity store as are available in the database. What you generally end up with is a very loose “allow/deny” set of permissions on the load balancing device that actually open the door for exploitation as well as caching of credentials that can lead to unauthorized access to the data source. This also leads to potential security risks from attempting to apply some of the same optimization techniques to SQL connections as is offered by application delivery solutions for TCP connections. For example, TCP multiplexing (sharing connections) is a common means of reusing web and application server connections to reduce latency (by eliminating the overhead associated with opening and closing TCP connections). Similar techniques at the database layer have been used by application servers for many years; connection pooling is not uncommon and is essentially duplicated at the application delivery tier through features like SQL multiplexing. Both connection pooling and SQL multiplexing incur security risks, as shared connections require shared credentials. So either every access to the database uses the same credentials (a significant negative when considering the loss of an audit trail) or we return to managing duplicate sets of credentials – one set at the application delivery tier and another at the database, which as noted earlier incurs additional management and security risks. YOU CAN’T WIN FOR LOSING Ultimately the decision to load balance SQL must be a combination of business and operational requirements. Many organizations successfully leverage load balancing of SQL as a means to achieve very high scale. Generally speaking the resulting solutions – such as those often touted by e-Bay - are based on sound architectural principles such as sharding and are designed as a strategic solution, not a tactical response to operational failures and they rarely involve inspection of inline SQL commands. Rather they are based on the ability to discern which database should be accessed given the function being invoked or type of data being accessed and then use a traditional database connection to connect to the appropriate database. This does not preclude the use of application delivery solutions as part of such an architecture, but rather indicates a need to collaborate across the various application delivery and infrastructure tiers to determine a strategy most likely to maintain high-availability, scalability, and security across the entire architecture. Load balancing SQL can be an effective means of addressing database scalability, but it should be approached with an eye toward its potential impact on security and operational management. What are the pros and cons to keeping SQL in Stored Procs versus Code Mission Impossible: Stateful Cloud Failover Infrastructure Scalability Pattern: Sharding Streams The Real News is Not that Facebook Serves Up 1 Trillion Pages a Month… SQL injection – past, present and future True DDoS Stories: SSL Connection Flood Why Layer 7 Load Balancing Doesn’t Suck Web App Performance: Think 1990s.2.1KViews0likes1Comment