Contacting F5 Support
Contacting F5 for support can sometimes feel like an overwhelming and daunting task if you're not prepared. Opening your case with accurate diagnostics, and a detailed description of your issues will help us route your case to the appropriate technicians, but where do you start? We'll help you prepare for your first or tenth call to support and ensure it's an easy process. Bookmark this page and stop worrying about what you'll need. Clear focus and a calm head during a critical issue is your best advantage. What You'll Need When Contacting Support There are several key pieces of information support will ask for regardless of what module you're opening a ticket on. It's best to have most or all of the data ready in case support asks. In our experience being over prepared is never a bad thing. Submit a QKView to iHealth - iHealth is supports quickest window into your system health, configuration, and any update requirements. This is the first and most important thing to have when opening a case with F5. Additional Log Files - The QKView provides up to 5MB of logs but often grabbing additional logs may include more information. MD5 checksums for all uploaded files - Generating MD5 Checksums ensures F5 support engineers can validate your log, tcpdumps, and qkviews. tcpdump Often if you're having issues with one or more virtual servers, a tcpdump will expedite understanding traffic flow. This can be something you do before contacting support and we at DevCentral always find it to be valuable information. In fact we spend our evenings capturing traffic for fun. Explicit Details of your issue! - Having detailed information on your failure cannot be stressed enough. You should know the overall status of the system when it failed, the traffic flow, and symptoms when contacting support. This will expedite your case to the appropriate engineer. Problem vagueness will delay your resolution. Severity Level - F5 provides categories for you to determine your issue severity.. Sev 1: Site Down - All network traffic has ceased; critical impact to business. Sev 2: Site At Risk - Primary unit failed; no redundant state. Site/System at risk of going down. Sev 3: Performance Degraded - Network traffic is partially functional causing some applications to be unreachable. Sev 4: General Assistance - This is for questions regarding configurations. This should be your default severity for troubleshooting non-critical issues or general questions about product functionality. There are several ways to contact support, and we've found success by opening a web case for all issues, even when calling in for support. This allows you to get files to F5 engineers quicker and expedite your case routing process prior to calling in. F5 Websupport- The websupport interface allows you to create and update cases quickly without having to call support. You will need to register|anchor your F5 Support account for websupport and it's best to do that BEFORE you have an issue. The web support ticket process will require your serial number or parent system ID. Phone - Standard, Premium, and Premium Plus support plans can call F5 for assistance. Have your serial number or parent system ID ready. Chat - Currently available for AWS hourly billed customers (BYOL uses standard support). See our AWS wiki for more information. Azure customers are currently BYOL only (bring your own license) and can purchases regular support plans. Gathering Logs The default QKView will gather 5MB of recent log activity but support may ask for additional logs to help diagnose your issue. Log into the BIG-IP CLI Create a tar archive called logfiles.tar.gz in /var/tmp directory containing all of the files in /var/log by typing the following command: tar -czpf /var/tmp/logfiles.tar.gz /var/log/* Create an MD5 Checksum of the file so support can validate the file Generating MD5 Checksums MD5 checksum files give support a method to validate your upload is free of problems. It's best to use the md5sum command directly on the BIG-IP to reduce potential issues by transferring the file off host prior to running MD5 tools. To create an md5sum: Log into the BIG-IP CLI Use the previously created logfiles.tar.gz from the above as example: md5sum /var/tmp/logfiles.tar.gz > /var/tmp/logfiles.tar.gz.md5 Use the CAT command to validate the contents of the md5 file: cat /var/tmp/logfiles.tar.gz.md5 You should see a result similar to: 1ebe43a0b0c7800256bfe94cdd079311 /var/tmp/logfiles.tar.gz576Views1like2CommentsWhat is iCall?
tl;dr - iCall is BIG-IP’s event-based granular automation system that enables comprehensive control over configuration and other system settings and objects. The main programmability points of entrance for BIG-IP are the data plane, the control plane, and the management plane. My bare bones description of the three: Data Plane - Client/server traffic on the wire and flowing through devices Control Plane - Tactical control of local system resources Management Plane - Strategic control of distributed system resources You might think iControl (our SOAP and REST API interface) fits the description of both the control and management planes, and whereas you’d be technically correct, iControl is better utilized as an external service in management or orchestration tools. The beauty of iCall is that it’s not an API at all—it’s lightweight, it’s built-in via tmsh, and it integrates seamlessly with the data plane where necessary (via iStats.) It is what we like to call control plane scripting. Do you remember relations and set theory from your early pre-algebra days? I thought so! Let me break it down in a helpful way: P = {(data plane, iRules), (control plane, iCall), (management plane, iControl)} iCall allows you to react dynamically to an event at a system level in real time. It can be as simple as generating a qkview in the event of a failover or executing a tcpdump on a server with too many failed logins. One use case I’ve considered from an operations perspective is in the event of a core dump to have iCall generate a qkview, take checksums of the qkview and the dump file, upload the qkview and generate a support case via the iHealth API, upload the core dumps to support via ftp with the case ID generated from iHealth, then notify the ops team with all the appropriate details. If I had a solution like that back in my customer days, it would have saved me 45 minutes easy each time this happened! iCall Components Three are three components to iCall: events, handlers, and scripts. Events An event is really what drives the primary reason to use iCall over iControl. A local system event (whether it’s a failover, excessive interface or application errors, too many failed logins) would ordinarily just be logged or from a system perspective, ignored altogether. But with iCall, events can be configured to force an action. At a high level, an event is "the message," some named object that has context (key value pairs), scope (pool, virtual, etc), origin (daemon, iRules), and a timestamp. Events occur when specific, configurable, pre-defined conditions are met. Example (placed in /config/user_alert.conf) alert local-http-10-2-80-1-80-DOWN "Pool /Common/my_pool member /Common/10.2.80.1:80 monitor status down" { exec command="tmsh generate sys icall event tcpdump context { { name ip value 10.2.80.1 } { name port value 80 } { name vlan value internal } { name count value 20 } }" } Handlers Within the iCall system, there are three types of handlers: triggered, periodic, and perpetual. Triggered A triggered handler is used to listen for and react to an event. Example (goes with the event example from above:) sys icall handler triggered tcpdump { script tcpdump subscriptions { tcpdump { event-name tcpdump } } } Periodic A periodic handler is used to react to an interval timer. Example: sys icall handler periodic poolcheck { first-occurrence 2017-07-14:11:00:00 interval 60 script poolcheck } Perpetual A perpetual handler is used under the control of a deamon. Example: handler perpetual core_restart_watch sys icall handler perpetual core_restart_watch { script core_restart_watch } Scripts And finally, we have the script! This is simply a tmsh script moved under the /sys icall area of the configuration that will “do stuff" in response to the handlers. Example (continuing the tcpdump event and triggered handler from above:) modify script tcpdump { app-service none definition { set date [clock format [clock seconds] -format "%Y%m%d%H%M%S"] foreach var { ip port count vlan } { set $var $EVENT::context($var) } exec tcpdump -ni $vlan -s0 -w /var/tmp/${ip}_${port}-${date}.pcap -c $count host $ip and port $port } description none events none } Resources iCall Codeshare Lightboard Lessons on iCall Threshold violation article highlighting periodic handler7.5KViews2likes10CommentsWhat is HTTP?
tl;dr - The Hypertext Transfer Protocol, or HTTP, is the predominant tool in the transferring of resources on the web, and a "must-know" for many application delivery concepts utilized on BIG-IP HTTP defines the structure of messages between web components such as browser or command line clients, servers like Apache or Nginx, and proxies like the BIG-IP. As most of our customers manage, optimize, and secure at least some HTTP traffic on their BIG-IP devices, it’s important to understand the protocol. This introductory article is the first of eleven parts on the HTTP protocol and how BIG-IP supports it. The series will take the following shape: What is HTTP? (this article) HTTP Series Part II - Underlying Protocols HTTP Series Part III - Terminology HTTP Series Part IV - Clients, Proxies, & Servers — Oh My! HTTP Series Part V - Profile Basic Settings HTTP Series Part VI - Profile Enforcement HTTP Series Part VII - Oneconnect HTTP Series Part VIII - Compression & Caching HTTP Series Part IX - Policies & iRules HTTP Series Part X- HTTP/2 A Little History Before the World Wide Web of Hypertext Markup Language (HTML) was pioneered, the internet was alive and well with bulletin boards, ftp, and gopher, among other applications. In fact, by the early 1990’s, ftp accounted for more than 50% of the internet traffic! But with the advent of HTML and HTTP, it only took a few years for the World Wide Web to completely rework the makeup of the internet. By the late 1990’s, more than 75% of the internet traffic belonged to the web. What makes up the web? Well get ready for a little acronym salad. There are three semantic components of the web: URIs, HTML, and HTTP. The URI is the Uniform Resource Identifier. Think of the URI as a pointer. The URI is a simple string and consists of three parts: the protocol, the server, and the resource. Consider https://devcentral.f5.com/s/articles/ . The protocol is https, the server is devcentral.f5.com, and the resources is /articles/. URL, which stands for Uniform Resource Locator, is actually a form of a URI, but for the most part they can be used interchangeably. I will clarify the difference in the terminology article. HTML is short for the HyperText Markup Language. It’s based on the more generic SGML, or Standard Generic Markup Language. HTML allows content creators to provide structure, text, pictures, and links to documents. In our context, this is the HTTP payload that BIG-IP might inspect, block, update, etc. HTTP as declared earlier, is the most common way of transferring resources on the web. It’s core functionality is a request/response relationship where messages are exchanged. An example of a GET message in the HTTP/1.1 version is shown in the image below. This is eye candy for now as we’ll dig in to the underlying protocols and HTTP terminology shown here in the following two articles. But take notice of the components we talked about earlier defined there. The protocol is identified as HTTP. Following the method is our resource /home, and the server is identified in the Host header. Also take note of all those silly carriage returns and new lines. Oh, the CRLF!! If you’ve dealt with monitors, you can feel our collective pain! HTTP Version History Whereas HTTP/2 has been done for more than two years now, current usage is growing but less than 20%, with HTTP/1.1 laboring along as the dominant player. We’ll cover version-specific nuances later in this series, but the major releases throughout the history of the web are: HTTP/0.9 - 1990 HTTP/1.0 - 1996 HTTP/1.1 - 1999 HTTP/2 - 2015 Given the advancements in technology in the last 18 years, the longevity of HTTP/1.1 is a testament to that committee (or an indictment on the HTTP/2 committee, you decide!) Needless-to-say, due to the longevity of HTTP/1.1, most of the industry expertise exists here. We’ll wrap this series with HTTP/2, but up front, know that it’s a pretty major departure from HTTP/1.1, most notably is that it is a binary protocol, whereas earlier versions of HTTP were all textual.1.5KViews4likes7CommentsWhat is Load Balancing?
tl;dr - Load Balancing is the process of distributing data across disparate services to provide redundancy, reliability, and improve performance. The entire intent of load balancing is to create a system that virtualizes the "service" from the physical servers that actually run that service. A more basic definition is to balance the load across a bunch of physical servers and make those servers look like one great big server to the outside world. There are many reasons to do this, but the primary drivers can be summarized as "scalability," "high availability," and "predictability." Scalability is the capability of dynamically, or easily, adapting to increased load without impacting existing performance. Service virtualization presented an interesting opportunity for scalability; if the service, or the point of user contact, was separated from the actual servers, scaling of the application would simply mean adding more servers or cloud resources which would not be visible to the end user. High Availability (HA) is the capability of a site to remain available and accessible even during the failure of one or more systems. Service virtualization also presented an opportunity for HA; if the point of user contact was separated from the actual servers, the failure of an individual server would not render the entire application unavailable. Predictability is a little less clear as it represents pieces of HA as well as some lessons learned along the way. However, predictability can best be described as the capability of having confidence and control in how the services are being delivered and when they are being delivered in regards to availability, performance, and so on. A Little Background Back in the early days of the commercial Internet, many would-be dot-com millionaires discovered a serious problem in their plans. Mainframes didn't have web server software (not until the AS/400e, anyway) and even if they did, they couldn't afford them on their start-up budgets. What they could afford was standard, off-the-shelf server hardware from one of the ubiquitous PC manufacturers. The problem for most of them? There was no way that a single PC-based server was ever going to handle the amount of traffic their idea would generate and if it went down, they were offline and out of business. Fortunately, some of those folks actually had plans to make their millions by solving that particular problem; thus was born the load balancing market. In the Beginning, There Was DNS Before there were any commercially available, purpose-built load balancing devices, there were many attempts to utilize existing technology to achieve the goals of scalability and HA. The most prevalent, and still used, technology was DNS round-robin. Domain name system (DNS) is the service that translates human-readable names (www.example.com) into machine recognized IP addresses. DNS also provided a way in which each request for name resolution could be answered with multiple IP addresses in different order. Figure 1: Basic DNS response for redundancy The first time a user requested resolution for www.example.com, the DNS server would hand back multiple addresses (one for each server that hosted the application) in order, say 1, 2, and 3. The next time, the DNS server would give back the same addresses, but this time as 2, 3, and 1. This solution was simple and provided the basic characteristics of what customer were looking for by distributing users sequentially across multiple physical machines using the name as the virtualization point. From a scalability standpoint, this solution worked remarkable well; probably the reason why derivatives of this method are still in use today particularly in regards to global load balancing or the distribution of load to different service points around the world. As the service needed to grow, all the business owner needed to do was add a new server, include its IP address in the DNS records, and voila, increased capacity. One note, however, is that DNS responses do have a maximum length that is typically allowed, so there is a potential to outgrow or scale beyond this solution. This solution did little to improve HA. First off, DNS has no capability of knowing if the servers listed are actually working or not, so if a server became unavailable and a user tried to access it before the DNS administrators knew of the failure and removed it from the DNS list, they might get an IP address for a server that didn't work. Proprietary Load Balancing in Software One of the first purpose-built solutions to the load balancing problem was the development of load balancing capabilities built directly into the application software or the operating system (OS) of the application server. While there were as many different implementations as there were companies who developed them, most of the solutions revolved around basic network trickery. For example, one such solution had all of the servers in a cluster listen to a "cluster IP" in addition to their own physical IP address. Figure 2: Proprietary cluster IP load balancing When the user attempted to connect to the service, they connected to the cluster IP instead of to the physical IP of the server. Whichever server in the cluster responded to the connection request first would redirect them to a physical IP address (either their own or another system in the cluster) and the service session would start. One of the key benefits of this solution is that the application developers could use a variety of information to determine which physical IP address the client should connect to. For instance, they could have each server in the cluster maintain a count of how many sessions each clustered member was already servicing and have any new requests directed to the least utilized server. Initially, the scalability of this solution was readily apparent. All you had to do was build a new server, add it to the cluster, and you grew the capacity of your application. Over time, however, the scalability of application-based load balancing came into question. Because the clustered members needed to stay in constant contact with each other concerning who the next connection should go to, the network traffic between the clustered members increased exponentially with each new server added to the cluster. The scalability was great as long as you didn't need to exceed a small number of servers. HA was dramatically increased with these solutions. However, since each iteration of intelligence-enabling HA characteristics had a corresponding server and network utilization impact, this also limited scalability. The other negative HA impact was in the realm of reliability. Network-Based Load balancing Hardware The second iteration of purpose-built load balancing came about as network-based appliances. These are the true founding fathers of today's Application Delivery Controllers. Because these boxes were application-neutral and resided outside of the application servers themselves, they could achieve their load balancing using much more straight-forward network techniques. In essence, these devices would present a virtual server address to the outside world and when users attempted to connect, it would forward the connection on the most appropriate real server doing bi-directional network address translation (NAT). Figure 3: Load balancing with network-based hardware The load balancer could control exactly which server received which connection and employed "health monitors" of increasing complexity to ensure that the application server (a real, physical server) was responding as needed; if not, it would automatically stop sending traffic to that server until it produced the desired response (indicating that the server was functioning properly). Although the health monitors were rarely as comprehensive as the ones built by the application developers themselves, the network-based hardware approach could provide at least basic load balancing services to nearly every application in a uniform, consistent manner—finally creating a truly virtualized service entry point unique to the application servers serving it. Scalability with this solution was only limited by the throughput of the load balancing equipment and the networks attached to it. It was not uncommon for organization replacing software-based load balancing with a hardware-based solution to see a dramatic drop in the utilization of their servers. HA was also dramatically reinforced with a hardware-based solution. Predictability was a core component added by the network-based load balancing hardware since it was much easier to predict where a new connection would be directed and much easier to manipulate. The advent of the network-based load balancer ushered in a whole new era in the architecture of applications. HA discussions that once revolved around "uptime" quickly became arguments about the meaning of "available" (if a user has to wait 30 seconds for a response, is it available? What about one minute?). This is the basis from which Application Delivery Controllers (ADCs) originated. The ADC Simply put, ADCs are what all good load balancers grew up to be. While most ADC conversations rarely mention load balancing, without the capabilities of the network-based hardware load balancer, they would be unable to affect application delivery at all. Today, we talk about security, availability, and performance, but the underlying load balancing technology is critical to the execution of all. Next Steps Ready to plunge into the next level of Load Balancing? Take a peek at these resources: Go Beyond POLB (Plain Old Load Balancing) The Cloud-Ready ADC BIG-IP Virtual Edition Products, The Virtual ADCs Your Application Delivery Network Has Been Missing Cloud Balancing: The Evolution of Global Server Load Balancing22KViews0likes1CommentWhat Is BIG-IP?
tl;dr - BIG-IP is a collection of hardware platforms and software solutions providing services focused on security, reliability, and performance. F5's BIG-IP is a family of products covering software and hardware designed around application availability, access control, and security solutions. That's right, the BIG-IP name is interchangeable between F5's software and hardware application delivery controller and security products. This is different from BIG-IQ, a suite of management and orchestration tools, and F5 Silverline, F5's SaaS platform. When people refer to BIG-IP this can mean a single software module in BIG-IP's software family or it could mean a hardware chassis sitting in your datacenter. This can sometimes cause a lot of confusion when people say they have question about "BIG-IP" but we'll break it down here to reduce the confusion. BIG-IP Software BIG-IP software products are licensed modules that run on top of F5's Traffic Management Operation System® (TMOS). This custom operating system is an event driven operating system designed specifically to inspect network and application traffic and make real-time decisions based on the configurations you provide. The BIG-IP software can run on hardware or can run in virtualized environments. Virtualized systems provide BIG-IP software functionality where hardware implementations are unavailable, including public clouds and various managed infrastructures where rack space is a critical commodity. BIG-IP Primary Software Modules BIG-IP Local Traffic Manager (LTM) - Central to F5's full traffic proxy functionality, LTM provides the platform for creating virtual servers, performance, service, protocol, authentication, and security profiles to define and shape your application traffic. Most other modules in the BIG-IP family use LTM as a foundation for enhanced services. BIG-IP DNS - Formerly Global Traffic Manager, BIG-IP DNS provides similar security and load balancing features that LTM offers but at a global/multi-site scale. BIG-IP DNS offers services to distribute and secure DNS traffic advertising your application namespaces. BIG-IP Access Policy Manager (APM) - Provides federation, SSO, application access policies, and secure web tunneling. Allow granular access to your various applications, virtualized desktop environments, or just go full VPN tunnel. Secure Web Gateway Services (SWG) - Paired with APM, SWG enables access policy control for internet usage. You can allow, block, verify and log traffic with APM's access policies allowing flexibility around your acceptable internet and public web application use. You know.... contractors and interns shouldn't use Facebook but you're not going to be responsible why the CFO can't access their cat pics. BIG-IP Application Security Manager (ASM) - This is F5's web application firewall (WAF) solution. Traditional firewalls and layer 3 protection don't understand the complexities of many web applications. ASM allows you to tailor acceptable and expected application behavior on a per application basis . Zero day, DoS, and click fraud all rely on traditional security device's inability to protect unique application needs; ASM fills the gap between traditional firewall and tailored granular application protection. BIG-IP Advanced Firewall Manager (AFM) - AFM is designed to reduce the hardware and extra hops required when ADC's are paired with traditional firewalls. Operating at L3/L4, AFM helps protect traffic destined for your data center. Paired with ASM, you can implement protection services at L3 - L7 for a full ADC and Security solution in one box or virtual environment. BIG-IP Hardware BIG-IP hardware offers several types of purpose-built custom solutions, all designed in-house by our fantastic engineers; no white boxes here. BIG-IP hardware is offered via series releases, each offering improvements for performance and features determined by customer requirements. These may include increased port capacity, traffic throughput, CPU performance, FPGA feature functionality for hardware-based scalability, and virtualization capabilities. There are two primary variations of BIG-IP hardware, single chassis design, or VIPRION modular designs. Each offer unique advantages for internal and collocated infrastructures. Updates in processor architecture, FPGA, and interface performance gains are common so we recommend referring to F5's hardware pagefor more information.61KViews2likes3CommentsWhat is BIG-IQ?
tl;dr - BIG-IQ centralizes management, licensing, monitoring, and analytics for your dispersed BIG-IP infrastructure. If you have more than a few F5 BIG-IP's within your organization, managing devices as separate entities will become an administrative bottleneck and slow application deployments. Deploying cloud applications, you're potentially managing thousands of systems and having to deal with traditionallymonolithic administrative functions is a simple no-go. Enter BIG-IQ. BIG-IQ enables administrators to centrally manage BIG-IP infrastructure across the IT landscape. BIG-IQ discovers, tracks, manages, and monitors physical and virtual BIG-IP devices - in the cloud, on premise, or co-located at your preferred datacenter. BIG-IQ is a stand alone product available from F5 partners, or available through the AWS Marketplace. BIG-IQ consolidates common management requirements including but not limited to: Device discovery and monitoring: You can discovery, track, and monitor BIG-IP devices - including key metrics including CPU/memory, disk usage, and availability status Centralized Software Upgrades: Centrally manage BIG-IP upgrades (TMOS v10.20 and up) by uploading the release images to BIG-IQ and orchestrating the process for managed BIG-IPs. License Management: Manage BIG-IP virtual edition licenses, granting and revoking as you spin up/down resources. You can create license pools for applications or tenants for provisioning. BIG-IP Configuration Backup/Restore: Use BIG-IQ as a central repository of BIG-IP config files through ad-hoc or scheduled processes. Archive config to long term storage via automated SFTP/SCP. BIG-IP Device Cluster Support: Monitor high availability statuses and BIG-IP Device clusters. Integration to F5 iHealth Support Features: Upload and read detailed health reports of your BIG-IP's under management. Change Management: Evaluate, stage, and deploy configuration changes to BIG-IP. Create snapshots and config restore points and audit historical changes so you know who to blame. 😉 Certificate Management: Deploy, renew, or change SSL certs. Alerts allow you to plan ahead before certificates expire. Role-Based Access Control (RBAC): BIG-IQ controls access to it's managed services with role-based access controls (RBAC). You can create granular controls to create view, edit, and deploy provisioned services. Prebuilt roles within BIG-IQ easily allow multiple IT disciplines access to the areas of expertise they need without over provisioning permissions. Fig. 1 BIG-IQ 5.2 - Device Health Management BIG-IQ centralizes statistics and analytics visibility, extending BIG-IP's AVR engine. BIG-IQ collects and aggregates statistics from BIG-IP devices, locally and in the cloud. View metrics such as transactions per second, client latency, response throughput. You can create RBAC roles so security teams have private access to view DDoS attack mitigations, firewall rules triggered, or WebSafe and MobileSafe management dashboards. The reporting extends across all modules BIG-IQ manages, drastically easing the pane-of-glass view we all appreciate from management applications. For further reading on BIG-IQ please check out the following links: BIG-IQ Centralized Management @ F5.com Getting Started with BIG-IQ @ F5 University DevCentral BIG-IQ BIG-IQ @ Amazon Marketplace7.8KViews1like1CommentWhat is an Application Delivery Controller - Part I
A Little History Application Delivery got its start in the form of network-based load balancing hardware. It is the essential foundation on which Application Delivery Controllers (ADCs) operate. The second iteration of purpose-built load balancing (following application-based proprietary systems) materialized in the form of network-based appliances. These are the true founding fathers of today's ADCs. Because these devices were application-neutral and resided outside of the application servers themselves, they could load balance using straightforward network techniques. In essence, these devices would present a "virtual server" address to the outside world, and when users attempted to connect, they would forward the connection to the most appropriate real server doing bi-directional network address translation (NAT). Figure 1: Network-based load balancing appliances. With the advent of virtualization and cloud computing, the third iteration of ADCs arrived as software delivered virtual editions intended to run on hypervisors. Virtual editions of application delivery services have the same breadth of features as those that run on purpose-built hardware and remove much of the complexity from moving application services between virtual, cloud, and hybrid environments. They allow organizations to quickly and easily spin-up application services in private or public cloud environments. Basic Application Delivery Terminology It would certainly help if everyone used the same lexicon; unfortunately, every vendor of load balancing devices (and, in turn, ADCs) seems to use different terminology. With a little explanation, however, the confusion surrounding this issue can easily be alleviated. Node, Host, Member, and Server Most ADCs have the concept of a node, host, member, or server; some have all four, but they mean different things. There are two basic concepts that they all try to express. One concept—usually called a node or server—is the idea of the physical or virtual server itself that will receive traffic from the ADC. This is synonymous with the IP address of the physical server and, in the absence of a ADC, would be the IP address that the server name (for example, www.example.com) would resolve to. We will refer to this concept as the host. The second concept is a member (sometimes, unfortunately, also called a node by some manufacturers). A member is usually a little more defined than a server/node in that it includes the TCP port of the actual application that will be receiving traffic. For instance, a server named www.example.com may resolve to an address of 172.16.1.10, which represents the server/node, and may have an application (a web server) running on TCP port 80, making the member address 172.16.1.10:80. Simply put, the member includes the definition of the application port as well as the IP address of the physical server. We will refer to this as the service. Why all the complication? Because the distinction between a physical server and the application services running on it allows the ADC to individually interact with the applications rather than the underlying hardware or hypervisor. A host (172.16.1.10) may have more than one service available (HTTP, FTP, DNS, and so on). By defining each application uniquely (172.16.1.10:80, 172.16.1.10:21, and 172.16.1.10:53), the ADC can apply unique load balancing and health monitoring based on the services instead of the host. However, there are still times when being able to interact with the host (like low-level health monitoring or when taking a server offline for maintenance) is extremely convenient. Most load balancing-based technology uses some concept to represent the host, or physical server, and another to represent the services available on it— in this case, simply host and services. Pool, Cluster, and Farm Load balancing allows organizations to distribute inbound application traffic across multiple back-end destinations, including cloud deployments. It is therefore a necessity to have the concept of a collection of back-end destinations. Pools, as we will refer to them (also known as clusters or farms) are collections of similar services available on any number of hosts. For instance, all services that offer the company web page would be collected into a pool called "company web page" and all services that offer e-commerce services would be collected into a pool called "e-commerce." The key element here is that all systems have a collective object that refers to "all similar services" and makes it easier to work with them as a single unit. This collective object—a pool—is almost always made up of services, not hosts. Virtual Server Although not always the case, today the term virtual server means a server hosting virtual machines. It is important to note that like the definition of services, virtual server usually includes the application port was well as the IP address. The term "virtual service" would be more in keeping with the IP:Port convention; but because most vendors, ADC and Cloud alike use virtual server, this article uses virtual server as well. Putting It All Together Putting all of these concepts together makes up the basic steps in load balancing. The ADC presents virtual servers to the outside world. Each virtual server points to a pool of services that reside on one or more physical hosts. Figure 2: Application Delivery comprises four basic concepts—virtual servers, pool/cluster, services, and hosts. While the diagram above may not be representative of a real-world deployment, it does provide the elemental structure for continuing a discussion about application delivery basics. ps Next Steps ReadWhat is Load Balancing?if you haven't already and check out What is an Application Delivery Controller -Part II.3.2KViews0likes1CommentWhat is the Edge?
Where oh where to begin? "The Edge" excitement today is reminiscent of "The Cloud" of many moons ago. Everyone, I mean EVERYONE, had a "to the cloud" product to advertise. CS Lewis (The Chronicles of Narnia) wrote an essay titled "The Death of Words" where he bemoaned the decay of words that transitioned from precise meanings to something far more vague. One example he used was gentleman, which had a clear objective meaning (a male above the station of yeoman whose family possessed a coat of arms) but had decayed (and is to this day) to a subjective state of referring to someone well-mannered. This is the case with industry shifts like cloud and edge, and totally works to the advantage of marketing/advertising. The result, however, is usually confusion. In this article, I'll briefly break down the edge in layman's terms, then link out to the additional reading you should do to familiarize yourself with the edge, why it's hot, and how F5 can help with your plans. What is edge computing? The edge, plainly, is all about distribution, taking services once available only in private datacenters and public clouds and shifting them out closer to where the requests are, whether those requests are coming from humans or machines. This shift of services is comprehensive, so while technologies from the infancy of the edge like CDNs are still in play, the new frontier of compute, security, apps, storage, etc, enhances the user experience and broadens the scope of real-time possibilities. CDNs were all about distributing content. The modern edge is all about application and data distribution. Where is the edge, though? But, you say, how is that not the cloud? Good question. Edge computing builds on the technology developed in the cloud era, where de-centralized compute and storage architectures were honed. But the clouds are still regional datacenters. A good example to bring clarity might be an industrial farm. Historically, data from these locations would be sent to a centralized datacenter or cloud for processing, and depending on the workloads, tractors or combines might be idle (or worse: errant) while waiting for feedback. With edge computing, a local node (consider this an enterprise edge) would be gathering all that data, processing, analyzing, and responding in real-time to the equipment, and then sending up to the datacenter/cloud anything relevant for further processing or reporting. Another example would be self-driving car or gaming technology, where perhaps the heavy compute for these is at the telco edge instead of having to backhaul all of it to a centralized processing hub. Where is the edge? Here, there, and everywhere. The edge, conceptually, can be at any point in between the user (be it human, animal, or machine) and the datacenter/cloud. Physically, though, understand that just like "serverless" applications still have to run on an actual server somewhere, edge technology isn't magic, it has to be hosted somewhere as well. The point is that host knows no borders; it can be in a provider, a telco, an enterprise, or even in your own home (see Lori's "Find My Cat" use case). The edge is coming for you The stats I've seen from Gartner and others are pretty shocking. 76% already have plans to deploy at the edge, and 75% of data will be processed at the edge by 2025? I'm no math major, but that sounds like one plus two, carry the three, uh, tomorrow! Are you ready for this? The good news is we are here to help. The best leaps forward in anything in our industry have always come from efforts bringing simplicity to the complexities. Abstraction is the key. Think of the progression of computer languages and how languages like C abstract the needs in Assembler, or how dynamically typed languages like python even abstract away the need for types. Or how hypervisors abstract lower level resources and allow you to carve out compute. Whether you're a netops persona thankful for tools that abstract BGP configurations from the differing syntax of various routers, or a developer thankful for libraries that abstract the nuances of different DNS providers so you can generate your SSL certificates with Let's Encrypt, all of that is abstraction. I like to know what's been abstracted. That's practical at times, but not often. Maybe in academia. Frankly, the cost associated to knowing "all the things" ins't one for which most orgs will pay. Volterra delivers that abstraction, to the compute stack and the infrastructure connective tissue, in spades, thus removing the tenuous manual stitching required to connect and secure your edge services. General Edge Resources Extending Adaptive Applications to the Edge Edge 2.0 Manifesto: Redefining Edge Computing Living on the Edge: How we got here Increasing Diversity of Location and Users is Driving Business to the Edge Application Edge Integration: A Study in Evolution The role of cloud in edge-native applications Edge Design & Data | The Edgevana Podcast (Youtube) Volterra Specific Resources Volterra and Power of the Distributed Cloud (Youtube) Multi-Cloud Networking with Volterra (Youtube) Network Edge App: Self-Service Demo (Youtube) Volterra.io Videos466Views4likes0Comments
An Illustrated Hands-on Intro to AWS VPC Networking
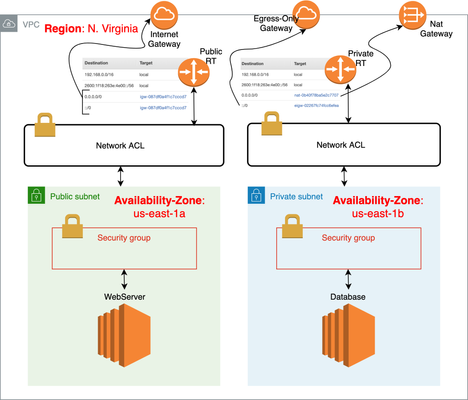
Quick Intro If you're one of those who knows a bit of networking but you feel uncomfortable touching AWS networking resources, then this article is for you. We're going to go through real AWS configuration and you can follow along to solidify your understanding. I'm going through the process of what I personally do to create 2 simple virtual machines, one in a private subnet and another one in a public subnet running Amazon Linux AMI instance. I will assume you already have an AWS account and corresponding credentials. If not, please go ahead and create your free tier AWS account. Just keep in mind that Amazon's equivalent to a Virtual Machine (VM) is known as EC2 instance. VPC, Subnets, Route Tables and Internet Gateways In short, we can think of Virtual Private Cloud (VPC) as our personal Data Centre. Our little private space in the cloud. Because it's our personal Data Centre, networking-wise we should have our own CIDR block. When we first create our VPC, a CIDR block is a compulsory field. Think of a CIDR block as the major subnet where all the other small subnets will be derived from. When we create subnets, we create them as smaller chunks from CIDR block. After we create subnets, there should be just a local route to access "objects" that belong to or are attached to the subnet. Other than that, if we need access to the Internet, we should create and attach an Internet Gateway (IGW) to our VPC and add a default route pointing to the IGW to route table. That should take care of it all. Our Topology for Reference This summarises what we're going to do. It might be helpful to use it as a reference while you follow along: Don't worry if you don't understand everything in the diagram above. As you follow along this hands-on article, you can come back to it and everything should make sense. What we'll do here I'll explain the following VPC components as we go along configuring them: Subnets Route Tables Internet Gateway NAT Gateway Egress-Only Gateway Quick Recap (I'll just quick summarise what we've done so far because our little virtual DC should be ready to go now!) We'll then perform the tests: Launching EC2 Instance from Amazon Marketplace (That's where we create a virtual machine) First attempt to connect via SSH (that's where we try to connect to our instance via SSH but fail! Hold on, I'll fix it!) Network ACLs and Security Groups (that's where I point the features that are to blame for our previous failed attempt and fix what's wrong) Connect via SSH again (now we're successful) Note that we only tested our Public instance above as it'd be very repetitive configuring Private instance so I added Private Instance config to Appendix section: Spinning Up Private EC2 Instance VPC Components The first logical question I get asked by those with little experience with AWS is which basic components do we need to build our core VPC infrastructure? First we pick an AWS Region: This is the region we are going to physically run our virtual infrastructure, i.e. our VPC. Even though your infrastructure is in the Cloud, Amazon has Data Centres (DC) around the world in order to provide first-class availability service to your resources if you need to. With that in mind, Amazon has many DCs located in many differentRegions(EU, Asia Pacific, US East, US West, etc). The more specific location of AWS DCs are called Availability Zones (AZ). That's where you'll find one (or more DCs). So, we create a VPC within a Region and specify a CIDR block and optionally request an Amazon assigned /56 IPv6 CIDR block: If you're a Network Engineer, this should sound familiar, right? Except for the fact that we're configuring our virtual DC in the Cloud. Subnets Now that we've got our own VPC, we need to create subnets within the CIDR block we defined (192.168.0.0/16). Notice that I also selected the option to retrieve anAmazon's provided IPv6 CIDR blockabove. That's because we can't choose an IPv6 CIDR block. We've got to stick to what Amazon automatically assigns to us if we want to use IPv6 addresses. For IPv6, Amazon always assigns a fixed /56 CIDR block and we can only create /64 subnets. Also, IPv6 addresses are always Public and there is no NAT by design. Our assigned CIDR block here was2600:1f18:263e:4e00::/56. Let's imagine we're hosting webserver/database tiersin 2 separate subnets but keep in mind this just for lab test purposes only. A real configuration would likely have instances in multiple AZs. For ourPublic WebServer Subnet, we'll use192.168.1.0/24and2600:1f18:263e:4e00:01:/64. For ourPrivate Database Subnet, we'll use192.168.2.0/24and2600:1f18:263e:4e00:02:/64 Here's how we create ourPublic WebServer Subneton Availability Zoneus-east-1a: Here's how we configure our Private Database Subnet: Notice that I putPrivate Database Subnetin a different Availability Zone. In real life, we'd likely create 1 public and 1 private subnet in one Availability Zone and another public and private subnet in a different Availability Zone for redundancy purposes as mentioned before. For this article, I'll stick to our config above for simplicity sake. That's just a learn by doing kind of article! :) Route Tables If we now look at the Route Table, we'll see that we now have 2 local routes similar to what would appear if we had configured 2 interfaces on a physical router: However, that's the default/main route table that AWS automatically created for our DevCentral VPC. If we want our Private Subnet to be really private, i.e. no Internet access for example, we can create a separate route table for it. Let's create 2 route tables, one named Public RT and the other Private RT: Private RT should be created in the same way as above with a different name. The last step is to associate our Public subnet to our Public RT and Private subnet to our Private RT. The association will bind the subnet to route table making them directly connected routes: Up to know, both tables look similar but as we configure Internet Gateway in next section, they will look different. Internet Gateway Yes, we want to make them different because we want Public RT to have direct access to the Internet. In order to accomplish that we need to create an Internet Gateway and attach it to our VPC: And lastly create a default IPv4/IPv6 route in Public RT pointing to Internet Gateway we've just created: So our Public route table will now look like this: EC2 instances created within Public Subnet should now have Internet access both using IPv4 and IPv6. NAT Gateway Our database server in the Private subnet will likely need outbound Internet access to install updates or for ssh access, right? So, first let's create a Public Subnet where our NAT gateway should reside: We then create a NAT gateway in above Public Subnet with an Elastic (Public) IPv4 address attached to it: Yes, NAT Gateways need a Public (Elastic) IPv4 address that is routable over the Internet. Next, we associate NAT Public Subnet to our Private Route Table like this: Lastly, we create a default route in our Private RT pointing to NAT gateway for IPv4 Internet traffic: We're pretty much done with IPv4. What about IPv6 Internet access in our Private subnet? Egress-Only Gateway As we know, IPv6 doesn't have NAT and all IPv6 addresses are Global so the trick here to make an EC2 instance using IPv6 to behave as if it was using a "private" IPv4 address behind NAT is to create an Egress-only Gateway and point a default IPv6 route to it. As the name implies, an Egress-only Gateway only allows outbound Internet traffic. Here we create one and and then add default IPv6 route (::/0) pointing to it: Quick Recap What we've done so far: Created VPC Created 2 Subnets (Private and Public) Created 2 Route tables (one for each Subnet) Attached Public Subnet to Public RT and Private Subnet to Private RT Created 1 Internet Gateway and added default routes (IPv4/IPv6) to our Public RT Created 1 NAT Gateway and added default IPv4 route to our Private RT Created 1 Egress-only Gateway and added default IPv6 route to our Private RT Are we ready to finally create an EC2 instance running Linux, for example, to test Internet connectivity from both Private and Public subnets? Launching EC2 Instance from Amazon Marketplace Before we get started, let's create a key-pair to access our EC2 instance via SSH: Our EC2 instances are accessed using a key-pair rather than a password. Notice that it automatically downloads the private key for us. Ok, let's create our EC2 instance. We need to click onLaunch Instanceand Select an image from AWS Marketplace: As seen above, I pickedAmazon Linux 2 AMIfor testing purposes. I selected the t2.micro type that only has 1 vCPU and 1 GB of memory. For the record, AWS Marketplace is a repository of AWS official images and Community images. Images are known as Amazon Machine Images (AMI). Amazon has many instance types based on the number of vCPUs available, memory, storage, etc. Think of it as how powerful you'd like your EC2 instance to be. We then configure our Instance Details by clicking onNext: Configure Instance Details button: I'll sum up what I've selected above: Network: we selected our VPC (DevCentral) Subnet: Public WebServer Subnet Auto-assign Public IP: Enabled Auto-assign IPv6 IP:Enabled The reason we selected "Enabled" to auto-assignment of IP addresses was because we want Amazon to automatically assign an Internet-routable Public IPv4 address to our instance. IPv6 addresses are always Internet-routable but I want Amazon to auto-assign an IPv6 address for me here so I selected Enabled to Auto-assign IPv6 IP too.. Notice that if we scroll down in the same screen above we could've also specified our private IPv4 address in the range of Public WebServer Subnet (192.168.1.0/24): The Public IPv4 address is automatically assigned by Amazon but once instance is rebooted or terminated it goes back to Amazon Public IPv4 pool. There is no guarantee that the same IPv4 address will be re-used. If we need an immutable fixed Public IPv4 address, we would need to add an Elastic IPv4 address to our VPC instead and then attach it to our EC2 instance. IPv6 address is greyed out because we opted for an auto-assigned IPv6 address, remember? We could've gone ahead and selected our storage type by clicking onNext: Add Storagebut I'll skip this. I'll add a Name tag of DevCentral-Public-Instance, select default Security Group assigned to our VPC as well as our previously created key-pair and lastly click on Launch to spin our instance up (Animation starts at Step 4): After that, if we click on Instances, we should see our instance is now assigned a Private as well as a Public IPv4 address: After a while, Instance State should change to Running: First Attempt to Connect via SSH If we click on Connect button above, we will get the instructions on how to SSH to our Public instance: Let's give it a go then: It didn't work! That would make me crack up once I got started with AWS, until I learn about Network ACLs and Security Groups! Network ACLs and Security Groups When we create a VPC, a default NACL and a Security Group are also created. All EC2 instances' interfaces belong to a Security Group and the subnet it belongs to have an associated NACL protecting it. NACL is a stateless Firewall that protects traffic coming in/out to/from Subnet. Security Group is a stateful Firewall that protects traffic coming in/out to/from an EC2 instance, more specifically its vNIC. The following simplified diagram shows that: What's the different between stateful and stateless firewall? A Security Group (stateful) rule that allows an outbound HTTP traffic, also allows return traffic corresponding to outbound request to be allowed back in. This is why it's called stateful as it keeps track of session state. A NACL (stateless) rule that allows an outbound HTTP traffic does not allow return traffic unless you create an inbound rule to allow it. This is why it's called stateless as it does not keep track of session state. Now let's try to work out why our SSH traffic was blocked. Is the problem in the default NACL? Let's have a look. This is what we see when we click onSubnets→ Public WebServer Subnet: As we can see above, the default NACL is NOT blocking our SSH traffic as it's allowing everything IN/OUT. Is the problem the default Security Group? This is what we see when we click onSecurity Groups→ sg-01.db...→ Inbound Rules: Yes! SSH traffic from my external client machine is being blocked by above inbound rule. The above rule says that our EC2 instance should allow ANY inbound traffic coming from other instances that also belong to above Security Group. That means that our external client traffic will not be accepted. We don't need to check outbound rules here because we know that stateful firewalls would allow outbound ssh return traffic back out. Creating a new Security Group To fix the above issue, let's do what we should've done while we were creating our EC2 instance. We first create a new Security Group: A newly created non-default SG comes with no inbound rules, i.e. nothing is allowed, not even traffic coming from other instances that belong to security group itself. There's always an explicit deny all rule in a security group, i.e. whatever is not explicitly allowed, is denied. For this reason, we'll explicitly allow SSH access like this: In real world, you can specify a more specific range for security purposes. And lastly we change our EC2 instance's SG to the new one by going toEC2 → Instances → <Name of Instance> → Networking → Change Security Groups: Another Window should appear and here's what we do: Connecting via SSH again Now let's try to connect via SSH again: It works! That's why it's always a good idea to create your own NACL and Security Group rules rather than sticking to the default ones. Appendix - Spinning Up EC2 instance in Private Subnet Let's create our private EC2 instance to test Internet access using our NAT gateway and Egress-Only Gateway here. Our Private RT has a NAT gateway for IPv4 Internet access and an Egress-Only Gateway for IPv6 Internet access as shown below: When we create our private EC2 instance, we won't enable Auto-assign Public IP (for IPv4) as seen below: It's not shown here, but when I got to the Security Group configuration part I selected the previous security group I created that allows SSH access from everyone for testing purposes. We could have created a new SG and added an SSH rule allowing access only from our local instances that belong to our 192.168.0.0/16 range to be more restrictive. Here's my Private Instance config if you'd like to replicate: Here's the SSH info I got when I clicked on Connect button: Here's my SSH test: All Internet tests passed and you should now have a good understanding of how to configure basic VPC components. I'd advise you to have a look at our full diagram again and any feedback about the animated GIFs would be appreciated. Did you like them? I found them better than using static images.2.1KViews1like13CommentsTroubleshooting BIG-IP - The Basics
Architecture 101 doesn't recommend going live withevery feature and complicated requirement enabled at launch. As such nor should your BIG-IP configuration. Yet reviewing countless Q&A and support cases, a lot of basic steps are overlooked. You may be so focused on tricking out that sweet iRule you forgot to enable a Client SSL profile or even as simple as forgetting to assign a SNAT pool. It happens to all of us and the best way to fix these problems is to reduce the complexity and start with the basics! Know Your Lingo Just like every other vendor BIG-IP does have some terminology unfamiliar to people outside of the network-speaking world. Once you have the common terms locked down, everything else will fall into place. Here's some of the terms used in this article that are handy to remember. vip - When we refer to a VIP, we're referring to the virtual IP assigned to a virtual server. Often we'll use the term VIP interchangeably referring to the virtual server. The vip is an object within BIG-IP that listens for address and service requests. A client send traffic to the vip which routes according to the virtual server's configuration. Node - The node is the server and service assigned to receive traffic from a virtual IP/Server. You will usually have more than one node defined to receive traffic from behind a virtual server. Pool - The virtual server will have a pool defined to send traffic to. Server nodes are assigned to one or more pools and the pool defines how to balance the traffic between them. ADC - BIG-IP is an Application Delivery Controller. Load Balancing, SSL Offloading, Compression, Acceleration, and traffic management all are features that define how an application delivery controller operate. SNAT - SNAT or secure network address translation translates the source IP address within a connection to a BIG-IP system IP address that you define. The destination node then uses that new source address as it's destination address when responding to the request. SNAT ensures server nodes always send traffic back through the BIG-IP system. There are always one-off cases where you don't want this but SNAT is your friend. Test Offline Hopefully you can test out your full application stack prior to going live. There are those times though when a go-live scenario is an application release nightmare and you're pushing out features left and right following cutover. That's no fun and it will make troubleshooting worse. If you have disaster recovery scenarios in place, you SHOULD have a redundant environment or something resembling one. You can test and troubleshoot against this offline "data center" or whatever you have running so you're not causing constant resets to your live application. If you have n+1 redundant application stacks (in production or other environment levels), test against the one with the least traffic (no traffic is preferred). Some people run backup procedures against offline data centers which is great if you're not troubleshooting a problem. Additional traffic will muddle the waters, especially if you're running vague tcpdumps. Don't test half of the application stack. Are you testing via IP only instead of using the DNS to resolve the application FQDN? Is the database in your offline instance synched? Make sure you're testing the full stack regardless of it being offline or not. If you had a DNS issue and were only using the IP, you'd never duplicate the problem. Whatever your offline instance is (test, stage, production, development) be wary of variables that will skew troubleshooting results; at best note them down for later inspection if needed. Even offline, applications can be chatty if integrated to other systems; federation, other data integration systems, directory syncs. If possible, temporarily suspend these external influences. It could be a simple as pausing a script or it could be suspending OLAP Cube genration within SQL. Noise always introduces variation. Be aware of these outside influences and inspect accordingly. Remember the Core Concepts There are two core needs for any ADC to operate properly and these need to work prior to dissecting your application. An ADC has to properly operate on your network and be able to speak to a client and server networks. These can be the same network and you're simply hair-pinning your ADC traffic, or you have segregated networking needs. Separate interfaces, properly configured trunks, tagged VLANS..... you know the drill. Trying to figure out why your application doesn't work is going to take a long time if BIG-IP stack isn't able to talk to your server network. Part two of this is remembering the core concepts of a virtual IP. You need a valid IP, you need a pool, you need a node and you need a port to listen on. These things do get overlooked so if you're surprised, don't be. It happens. System Requirements Can you reach the BIG-IP from the client network you're testing on? An admin can slide a firewall change affecting application A and inadvertently break access to application B, C, D... Making sure you can reach your BIG-IP from all required networks is sometimes a good thing to check. Believe me, this is an issue more than we like to admit. Is BIG-IP accepting and distributing traffic properly? If you're building your first application, this is a normal step. If this is your 30th application, you assume BIG-IP is behaving properly. There are cases where you'll need to step back and make sure BIG-IP is receiving traffic on listening interfaces and attempting to distribute traffic to your nodes. You can check BIG-IP statistics for some basic sanity checks but it always helps to run a tcpdump or spin up Wireshark to just give you that warm and fuzzy feeling of self assurance. Virtual IP Requirements Is your VIP on a valid client network and listening? It's easy to build a VIP for network X but select network Y for VLAN and Tunnel Traffic options. Port scan from a client to validate! Does your VIP have a valid pool and active pool members ready to receive client traffic? A surprising amount of support calls are resolved because the admin, in haste, just threw a tcp or tcp_half_open monitor to get the node available in the pool and the service behind the required port was actually down. If you're hurrying the basics, you're going to have a bad time! Make sure those nodes are up and listening on proper monitors, and they're available for use in your intended application pool. Is your traffic going to BIG-IP but you're not seeing anything come back? Are you running asynchronous routing? If so, did you remember to SNAT? A very common issue is misunderstanding when SNAT is needed. Many times we'll have a developer or admin state "but I need to see the source IP of the client traffic"... that's a separate problem. You're not going to see anything if your application works. Either SNAT your traffic or make BIG-IP your outbound application gateway. SNAT is not discussion, it's a way of life! Read up heavily on this hopefully PRIOR to implementation but if you don't, you'll just have some additional clean up down the road. Leave that for the intern. Reduce Complexity Overly complex installations require a lot of troubleshooting if something goes wrong during go-live. This is often why people do cutovers through staged releases; they're releasing smaller changes that can be easily managed. When a problem arises, it's very helpful to isolate the issue quickly and reduced complexity or starting with simple problem solving is your best bet. Remember that firewall admin that slipped in an ACL change that broke your application? If you didn't start with basics, you'd still be checking certificate dates, http profiles, and iRule syntax before you had the epiphany to see if ANY traffic was reaching your BIG-IP. As in testing offline, if possible use an offline datacenter. This lowers the traffic significantly and can make tcpdumps quite manageable. Disable all but one node. Reducing the client traffic to a single server node eases traffic inspection by an order of magnitude. If the problem you're solving is isolated to a single back end server, this too can also speed up the isolation process. Drop out of SSL and go unencrypted. If you're having "weird" issues, is it reproducible with non-SSL traffic? This may not always be as easy as it sounds, but being able to determine if encryption or security is playing a problematic role can speed up troubleshooting significantly. Does the application work without BIG-IP involved? Sounds silly but it's a valid question and where you should generally start. Make sure the application responds with basic functionality because ADC stacks for all their value, do add complexity to your environment. Being able to segregate the two for sanity checks is sometimes a good idea. Your vendor may also force you to do this if you call them with an application question. Or lie to them. That's cool too. Additional Tools for Diagnosing Problems I've run many applications behind BIG-IP and my toolset has remained mostly unchanged, mostly. Sometimes I start a little too deep for basic troubleshooting by diving into a packet capture from the get go, but I've used Wireshark enough that it's second nature now. As an application owner, all of your tools for problem diagnosis should be second nature too. Wireshark - I have to say I started out with Bloodhound (the Microsoft internal network monitor tool) way back in the NT 3.51 days. But when Wireshark released, it was a game changer. Being able to easily reassemble VOIP traffic into a listenable wav file to illustrate to a customer the jitter analysis in the tcp dump was amazing. Nowadays, there are plenty of players in the packet capture/analysis game, but there's a reason Wireshark is a verb; it's the standard... and we have an F5 Wireshark plugin for it too. tcpdump/ssldump - Knowing how to run tcpdumpandssldump on your BIG-IP is a requirement when contacting support so you might as well learn it. It'll end up coming in handy down the road when you also need to run ring dumps from a server looking for problematic traffic. Nmap - Install it everywhere. It's available for every operating system so there's no reason not to have it installed. Quickly analyze system availability and determine if the application's even listening to your requests. Nmap can do a lot more but as an advanced port scanner, it's all you'll ever need. Openssl - It's good to run Openssl for many reasons, from certificate analysis and CSR creation, to running your own CA for testing. The bonus for troubleshooting is the s_client SSL/TLS program. Connect and see what happens behind the SSL/TLS negotiation without needing a packet capture. Security professionals, networks admins, and application owners rely on Openssl's s_client to validate their TLS configurations. Curl - The website is down. Is it? Or is it your browser's inability to pass traffic due to the 30 extensions you have running? Curl is your site's sanity check to see exactly what's loading. It's quick and painless and can answer several initial troubleshooting questions right off the bat. And it does TLS so you can even overlap your Openssl s_client tests if you need. HttpWatch or Fiddler - These are the real winners here when troubleshooting an application response. Especially when you don't own the entire application stack. Each have their strengths and weaknesses but between the two, you can diagnose almost any web application issue quickly. Is the web site responding? Are you receiving the correct certificate? Is the data loading after CSS? What's that weird 3rd party script running? All can be answered with either of these tools. All of these recommendations were written up based on real support calls made by competent administrators who are new to BIG-IP or are new to their role as application administrator. If you're a developer and are new to BIG-IP, welcome and don't feel bad, we all started out making the exact same mistakes. Practice makes perfect so dive into your BIG-IP environment or purchase a BIG-IP Developer Lab License for yourself just to play around with. Hopefully you're feeling only slightly frustrated but just remember to break down your problems and take them one at a time. It's a good life lesson but it's also how you're going to fix your BIG-IP too.7.9KViews1like2Comments